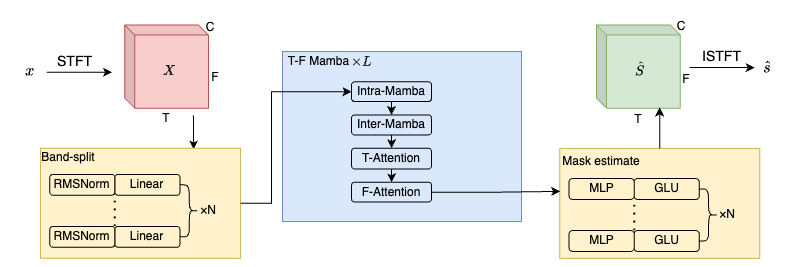
Recent years, with the ongoing development of deep learning, data-driven approaches have achieved remarkable success in music source separation. However, RNN-based methods have limited modeling capabilities, and Transformer-based methods have high computational complexity, limiting their practical applications. Due to the robust performance and the reduced computational requirements, Mamba has recently attracted significant attention. In this paper, we proposed a state space based model, namely BS-Mamba for music source separation. The BS-Roformer was adopted as the foundational framework and the Rope-Transformer within the framework was replaced with Mamba blocks. Specifically, we designed a T-F Mamba structure that combines Mamba block with multi-head self-attention, broadening contextual modeling capabilities. Experiment results show that BS-Mamba presents significant advantages in music source separation. We achieved comparable performance with only 50\% of parameters compared to BS-Roformer. The proposed model achieves a signal-to-distortion (SDR) of 9.96dB on the MUSDB18-HQ dataset without using extra data.